Оглавление
What are Threads
14.1–14.2 в первой книжке core java
общие штуки, чем отличаются потоки от процессов, многопоточность на практике, context switch, process control blocks, как запустить новый поток, как прервать поток, почему не стоит использовать Thread.stop(), как справляться с InterruptedException
Общие штуки. Операционная система выделяет куски ЦПУ-времени для каждого запущенного процесса, тем самым создавая впечатление того, что всё работает параллельно, так что количество “одновременно” работающих процессов не ограничено количеством процессоров (ядер). По аналогии внутри одной программы может быть создано несколько потоков (thread), которые будут выполняться одновременно. Programs that can rum more than one thread at once are said to be multithreaded.
Процессы и потоки. Разница между несколькими процессами и потоками в том, что каждый процесс имеет свой отдельный набор переменных (данных), в то время как потоки разделяют между собой одни и те же данные. Плюс общих данных в том, что это делает взаимодействие между потоками более эффективным, минус в том, что всё становится немного сложнее и непредсказуемее, придётся синхронизировать ресурсы, используемые совместно.
Необходимость в многопоточности возникает в самых простых случаях: например, когда надо прерывать выполнение какого-нибудь затратного по времени процесса, а не ждать его завершения. В общем случае многопоточность нужна для того, чтобы:
- эффективнее использовать процессорное время одного CPU (одного ядра). Это как раз относится к случаю, когда выполняется какой-то затратный процесс и нужно, чтобы на фоне него можно было выполнять ещё какую-то работу (поток с отрисовкой GUI приложения на фоне потока с выполнением какой-то логики).
- эффективнее использовать несколько CPU, чтобы распределить работу между ними.
- улучшение user experience относительно responsiveness и fairness — это всё частные случаи предыдущих пунктов. Отзывчивость = например, давать процессорное время на отрисовку GUI и взаимодействие с программой в то время, как она выполняет что-то полезное. Fairness = например, обрабатывать несколько запросов к серверу одновременно, жертвуя производительностью при выполнении каждого отдельного запроса.
Multithreading Costs, Context Switch. Для того, чтобы переключиться от одного потока к другому, CPU нужно сохранить куда-то все локальные данные вроде program counter’а, каких-то регистров и других данных, которые там нужны потоку. Все эти данные для каждого потока хранятся в process control блоках (PCB), которые там уже объединены в какую-то структуру данных, а сам процесс называется context switch‘ем. Выгрузка и загрузка этих данных занимает некоторое время, тут также стоит учитывать то, как часто conext switch происходит за малые промежутки времени. Ну и помимо time expenses есть ещё очевидные memory expenses: если создать кучу потоков, то это потребует некоторое количество дополнительной памяти.
Как запустить новый поток. Чтобы запустить код в отдельном потоке достаточно просто создать объект класса Thread, передав ему код, который надо запустить через функциональный интерфейс Runnable (лямбда выражением просто можно). И после этого надо будет вызвать thread.start(). Раньше было принято также наследовать свой класс от Thread, в котором переопределять метод run(), так что бы достаточно просто было написать new MyThread().run() для запуска нового потока. Однако такой подход не рекомендуется, потому что каждый раз выделять новый поток на каждую задачу — слишком жирно, надо разделять задачи, которые требуется выполнить, и механизм для их выполнения.
Прерывание потоков. Поток может завершиться естественным образом, если происходит возвращение из запущенного метода run(), или, когда там выбрасывается неперехваченное исключение. Можно также использовать метод Thread.stop() из другого потока, однако сейчас этот метод устарел:
This method is inherently unsafe. Stopping a thread with Thread.stop causes it to unlock all of the monitors that it has locked (as a natural consequence of the unchecked ThreadDeath exception propagating up the stack). If any of the objects previously protected by these monitors were in an inconsistent state, the damaged objects become visible to other threads, potentially resulting in arbitrary behavior. Many uses of stop should be replaced by code that simply modifies some variable to indicate that the target thread should stop running. The target thread should check this variable regularly, and return from its run method in an orderly fashion if the variable indicates that it is to stop running. If the target thread waits for long periods (on a condition variable, for example), the interrupt method should be used to interrupt the wait.
Другие способы прервать поток. Однако, кроме Thread.stop() нет другого способа насильно завершить поток, разве что вызвать Thread.interrup(), чтобы запросить завершение треда. Это выставляет флаг внутри потока, переводя его в interrupted status. Thread.currentThread() — чтобы получить доступ к текущему потоку, curentThread.isInterrupted() — чтобы проверить, не был ли прерыван тред. (Есть ещё статический метод interrupted, который возвращает флаг для текущего потока, и сразу же его сбрасывает в false.) Однако, если поток заблокирован (например, если у него вызвали sleep или wait), то у него просто нет шанса на то, чтобы завершиться. Поэтому в таком случае выбрасывается InterruptedException (это checked exception, так что пользователь обязан корректно его перехватить).
Нет чёткого никакого требования на уровне ЯП касательно того, когда “прерванный” поток должен завершиться, прерывание — это просто указание на то, что потоку надо бы завершиться.
Handling InterruptedException. Не стоит писать штук вроде:
try {
sleep(100);
} catch (InterruptedException e) { }
Даже, если ничего не получается придумать, то всегда есть выбор из вот такимх универсальных вариантов:
- Можно проглотить исключение и всё-таки выставить флаг через
Thread.currentThread().interrupt().
- А можно просто перебросить исключение выше по иерархии, указав
throws InterruptedException в объявлении метода.
Thread States
14.3 в первой книжке core java
в каких состояниях может находиться поток, как проходит цикл жизни потока, какие-то методы, связанные с этим и общие слова
Состояния потока. Потоки могут быть в одном из следующих состояний:
- New
- Runnable
- Blocked
- Waiting
- Timed waiting
- Terminated
Для определения текущего состояния достаточно вызвать Thread.getState(), который вернёт Thread.State.
New threads. Это начальное состояние потоков, с которым они создаются. В этом состоянии они ещё не запущены.
Runnable Threads. Как только был вызван метод start, поток становится runnable. При этом он необязательно выполняется прямо конкретно сейчас, он может быть на паузе, пока выполняются другие потоки, но операционная система может дать ему шанс немного поработать. Операционная система опирается на определённый список приоритетов (которые будут обсуждены несколько позже), когда выбирает, какой поток возобновить следующим. Такой вариант распределения ресурсов между потоками называется preemptive scheduling. Non-preemptive (cooperative) scheduling — это, когда процесс отпускает ресурсы только, когда он завершается или переходит в ждущее состояние, то есть он не прерывается операционной системой.
Blocked and Waiting Threads. Если поток находится в одном из этих состояний, то он временно неактивен, потребляет минимальное количество ресурсов, thread scheduler сам решает, когда заново активировать такие потоки:
- Когда поток пытается достать intrinsic object lock (что бы это ни значило, это будет объяснено позже), который захвачен каким-то другим потоком, то этот поток переходит в заблокированное состояние. Выходит из заблокированного состояния только, когда все остальные потоки отпустят этот lock.
- Когда поток ждёт, пока другой поток уведомит thread scheduler о condition (что бы это ни значило, это будет объяснено позже). Конкретно это происходит при вызове
Object.wait или Thread.join, или, когда поток поток ждёт Lock или Condition из пакета java.util.concurrent. На практике разница между blocked и waiting состояниями не так существенна.
- Некоторые методы, имеют параметры тайм-аута, и они переводят поток в timed waiting state. И поток находится в этом состоянии, пока не закончится таймер, или, пока не поступит подходящее уведомление.
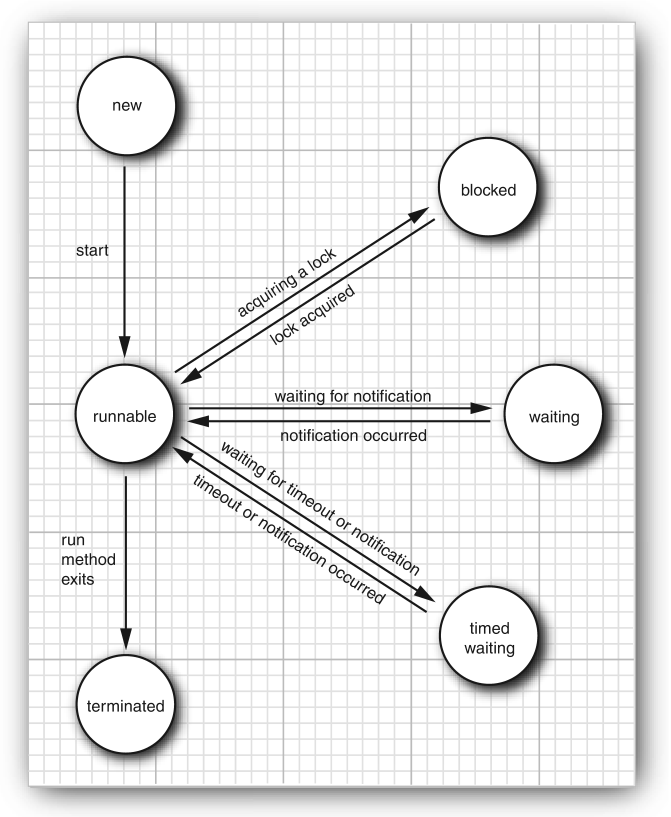
Как выбирается следующий поток. Когда поток переходит в заблокированное или ждущее состояние, thread scheduler выделяет ресурсы следующему потоку в очереди. Когда поток снова активируется (например, когда завершается таймер или когда поток получил lock), scheduler сравнивает приоритет этого потока с приоритетами текущих runnable потоков, и в зависимости от этого, возможно, запускает этот поток.
Некоторые методы, связанные с этими состояниями:
Thread.join() — ждать, пока не завершится этот поток.Thread.join(long millis) — ждать указанное время или, пока не завершится этот поток.Thread.suspend() — прервать выполнение потока. Этот метод устарел.Thread.resume() — продолжить выполнение потока, можно вызвать только после вызова метода suspend(). Этот метод устарел.
Terminated Threads. Поток завершается по одной из следующих причин:
- Поток завершается естественным образом, когда происходит возвращение из метода
run.
- Поток завершается выбросом исключения в методе
run.
- А ещё можно остановить методом
stop, но, как уже упоминалось, этот метод устарел. В сущности его вызов выбрасывает исключение ThreadDeath, так что это в каком-то смысле частный вариант предыдущего случая.
Thread Properties
14.4 в первой книжке core java
приоритеты потоков, платформозависимость потоков, какие-то методы, пример, как можно всё заруинить, если самому выставлять приоритеты потоков, daemon threads, handlers for uncaught exceptions, thread groups
Thread Priorities
Thread Priorities. Каждый поток имеет свой приоритет. По умолчанию приоритет нового потока наследуется от потока, в котором этот поток был создан, но можно задать и конкретный приоритет, который обозначается целыми числами от 1 до 10 (MIN_PRIORITY = 1, NORM_PRIORITY = 5, MAX_PRIORITY = 10). Всякий раз, когда thread scheduler’у надо выбрать новый поток, он предпочитает потоки с более высокими приоритетами потокам с низкими.
Приоритеты потоков очень сильно зависят от конкретной платформы. Приоритеты, определённые внутри джамбы отображаются в приоритеты внутри host платформы, в которой уже может быть больше или меньше уровней приоритета, так что возможно, some of the java priorities will map to the same operating system level. Может быть и такое, что в хост платформе выставленные приоритеты и вовсе будут игнорироваться. В частности по этой причине обычно нет смысла модифицировать приоритеты потоков, и уж тем более полагаться на них при определении логики работы программ.
А ещё можно загнать себя вот в такую ловушку: если выставить максимальный приоритет для потоков, которые никогда не становятся неактивными, то они не дадут никакого шанса другим потокам, потому что всякий раз thread scheduler будет выбирать эти high priority потоки.
Некоторые методы, связанные со всем этим:
Thread.setPriority(int) — просто выставляет приоритет.static yield() — текущий поток уступает другим потокам с большими или такими же приоритетами.
Daemon Threads
Чтобы сделать из потока daemon thread, достаточно вызвать метод thread.setDaemon(true). Такие потоки только лишь служат другим тредам, например, апдейтят или очищают что-то за ними. То есть сами по себе, в отрыве от логически связанных с ними потоками, они никакого смысла не имеют. Так что, когда остаются только daemon потоки, виртуальную машину можно останавливать. Ни в коем случае нельзя использовать daemon потоки для доступа к каким-то ресурсам, потому что то, в какой момент они остановятся, — не определено.
Handlers for Uncaught Exceptions
Если в методе run выбрасывается неперехваченное исключение, то выполнение потока прерывается. И его можно только попробовать перехватить внутри метода run, а перебросить выше — нельзя, потому что в объявлении run по по нятным причинам нельзя указать то, какими проверяемыми исключениями он кидается. Для этого прямо перед тем, как поток умирает, исключение передаётся handler’у для непойманных исключений:
Thread.UncaughtExceptionHandler {
void uncaughtException(Thread t, Throwable e)
}
(Default) uncaught exception handler. Для любого потока можно задать uncaught exception handler с помощью метода setUncaughtExceptionHandler для конкретного потока. А можно задать дефолтный handler и для всех потоков сразу с помощью статического метода с мега-длинным названием static Thread.setDefaultUncaughtExceptionHandler. Такой дефолтный handler может быть использован, например, для логирования ошибок в специальный фаел. По умолчанию дефолтный handler выставлен в null.
Thread Group. По умолчанию все потоки принадлежат одной группе, но можно создавать и кастомные группы потоков (которые, впрочем, всё ещё будут находиться внутри дефолтной группы). То, какой uncaught exception handler будет использоваться по умолчанию в рамках группы определяется, собственно, внутри объекта-группы. ThreadGroup — как раз объект для групп потоков и он имплементирует интерфейс Thread.UncaughtExceptionHandler. При этом группы потоков могут содержать другие группы потоков, так что получается такая древовидная штука. Конструктор ThreadGroup создаёт группу и в качестве родительской задаёт группу текущего потока. Ну, или можно самому указать группу, которую надо использовать в качестве родительской (но, как я понимаю, снаружи из потока нельзя достать его группу).
Как работают handler’ы для групп потоков. Таким образом, если для потока не задан конкретный uncaught exception handler, вызывается метод uncaughtException для группы потоков, в которой находится поток, в котором возникла ошибка. И дальше этот предпринимает следующие действия:
- Если у группы есть родительская группа, то метод
uncaughtException вызывается для родительской группы с теми же аргументами.
- Иначе, если выставлен дефолтный handler, то вызывается он.
- Иначе, если неперехваченное исключение — это
ThreadDeath, то ничего не происходит, потому что это исключение нарочно выбрасывается при вызове устаревшего Thread.stop для остановки выполнения потока.
- Иначе в
System.err просто печатается stack trace и содержание исключения.
public void uncaughtException(Thread t, Throwable e) {
if (parent != null) {
parent.uncaughtException(t, e);
} else {
Thread.UncaughtExceptionHandler ueh =
Thread.getDefaultUncaughtExceptionHandler();
if (ueh != null) {
ueh.uncaughtException(t, e);
} else if (!(e instanceof ThreadDeath)) {
System.err.print("Exception in thread \"" + t.getName() + "\" ");
e.printStackTrace(System.err);
}
}
}
Вот это стандартное поведение особо смысла не имеет, потому что в конечном итоге всё равно вызывается стандартный handler для исключений. Предполагается, что этот метод будет переопределён его пользователями, чтобы он имел более осмысленное поведение.
Однако есть гораздо более лучшие приколы для оперирования с наборами потоков, чем вот эти группы потоков, поэтому эти все штуки в книжке особо подробно не рассматриваются (собственно, как и многопоточность в целом).
Synchronization
14.5 в первой книжке core java
race condition (race hazard), пример этого состояния
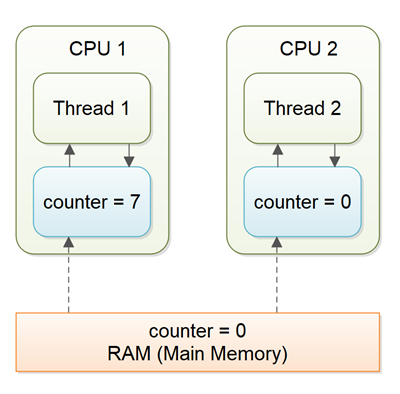
Общие слова. На практике в большинстве случаев в многопоточных приложениях два и более потоков могут одновременно взаимодействовать с одними и теми же данными, из-за чего данные могут повредиться, если доступ будет производиться в неопределённом порядке. Когда такое происходит, то это называют ещё race condition или race hazard (например, когда один поток пытается получить доступ к куску памяти, в который в этот момент пишет другой поток).
An Example of a Race Condition
Чтобы избежать повреждения данных, разделяемых несколькими потоками, нужно синхронизировать доступ к данным. Для демонстрации race condition можно рассмотреть небольшую программу, которая симулирует банк с несколькими счетами, которые пересылают транзакции друг другу. Мы попробуем дёргать метод пересылки денег из нескольких потоков одновременно для симуляции race condition.
Вот это главный класс Bank, который занимается переводами денег между банковскими счетами.
import java.util.Arrays;
import java.util.stream.DoubleStream;
class Bank {
private static final int ACCOUNTS_COUNT = 20;
// max amount of money per single transaction
private static final double MAX_AMOUNT = 1000.0;
// max delay between two transactions in a thread
private static final int MAX_DELAY = 10;
private double[] accounts;
/**
* Generates a collection of bank accounts with randomized accounts
* balances.
*/
public Bank() {
accounts = new double[ACCOUNTS_COUNT];
Arrays.fill(accounts, 5 * MAX_AMOUNT);
}
/**
* For simplicity we are not checking, if the {@code from} account has
* enough money to transfer money to the {@code to} bank account.
*/
public void transfer(int from, int to, double amount) {
System.out.println(Thread.currentThread());
accounts[from] -= amount;
System.out.printf("Money (%.2f) has been sent from %d to %d\n",
amount, from, to);
accounts[to] += amount;
System.out.printf("(%d -> %d) Money received. Total Balance: %10.2f\n",
from, to, getTotalBalance());
}
/**
* Returns the total amount of money stored in the bank.
*/
public double getTotalBalance() {
return DoubleStream.of(accounts).sum();
}
public static void main(String[] args) {
Bank bank = new Bank();
// each bank account sends a random amount of money to the random
// bank account from a separate thread
for (int i = 0; i < ACCOUNTS_COUNT; i++) {
int from = i;
Thread t = new Thread(() -> {
try {
while (true) {
int to = (int) (ACCOUNTS_COUNT * Math.random());
if (to == from) {
to = (to + 1) % ACCOUNTS_COUNT;
}
double amount = MAX_AMOUNT * Math.random();
bank.transfer(from, to, amount);
Thread.sleep((int) (MAX_DELAY * Math.random()));
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
t.start();
}
}
}
Проблема в том, что иногда потоки могут быть прерваны прямо в момент пересылки денег, из-за чего, например, если проверить сумму балансов на всех счетах в момент, когда некоторые из транзакций ещё не завершились, то она может оказаться меньше, чем есть на самом деле в теории.
Thread[Thread-19,5,main]
Money (917.92) has been sent from 19 to 11
(19 -> 11) Money received. Total Balance: 100000.00
Thread[Thread-11,5,main]
Thread[Thread-1,5,main]
Money (666.94) has been sent from 1 to 3
Thread[Thread-8,5,main]
(1 -> 3) Money received. Total Balance: 99877.79
Thread[Thread-5,5,main]
Money (582.36) has been sent from 5 to 10
(5 -> 10) Money received. Total Balance: 99250.18
Money (627.62) has been sent from 8 to 9
(8 -> 9) Money received. Total Balance: 99877.79
Money (122.21) has been sent from 11 to 0
(11 -> 0) Money received. Total Balance: 100000.00
Кроме того проблема может возникнуть, когда два потока одновременно выполняют строку кода accounts[to] += amount. Это не атомарная операция, она включает в себя несколько действий:
- Загрузить
accounts[to] в регистр.
- Добавить к значению в регистре
amount.
- Выгрузить из регистра результат обратно в
acounts[to].
Проблема может возникнуть, например, если какой-то второй поток прерывает выполнение текущего (первого) потока после выполнения второго шага. Допустим, второй поток модифицирует значение accounts[to], после чего управление опять передаётся в первый, который выгружает из временного регистра устаревшее значение, тем самым полностью отменяя результат работы второго потока. Таким образом, данные становятся повреждёнными.
Однако вероятность того, что такая ошибка произойдёт даже с учётом того, что в каждом потоке есть всего лишь несколько строк кода, очень мала, так что, возможно, эта ошибка в некоторых случаях даже не стоит того, чтобы пытаться исправить её. Но её надо принимать во внимание, в особенности, если, например, предполагается, что программа будет запущена на протяжении долгого времени.
Lock Objects
Synchronized keyword и lock объекты. Есть два основных механизма для защиты блока кода от concurrent доступа из двух разных потоков. Для этого в джемпере есть ключевое слово synchronized, и ещё есть объекты класса ReentrantLock. Ключевое слово synchronized автоматически защищает блок кода от одновременного доступа из разных потоков, в сущности то же самое можно сделать с помощью java.util.concurrent фреймворка. И сначала будет рассмотрен вот етот немного cumbersome способ с помощью lock объектов, а не простое и удобное synchronized keyword.
myLock.lock(); // a ReentrantLock object
try {
// critical section
} finally {
// Make sure the lock is unlocked even if an exception is thrown.
// Otherwise, in case an unhandled exception is thrown, all other
// threads will be locked forever.
myLock.unlock();
// Ещё надо убедиться в том, что shared объект не повреждён прежде, чем
// к нему получат доступ другие объекты
}
Вот такая конструкция гарантирует, что в выделенной критической секции в каждый момент времени находится только один поток. Как только один из потоков доходит до строки myLock.lock(), он запирает lock-объект, и все остальные потоки стопорятся на этой строке до тех пор, пока тот первый поток не откроет lock-объект. Эта штука похожа на развёрнутое try-with-resources-statement: там тоже в конце в finally освобождаются ресурсы, но здесь оно бы не сработало, во-первых, потому что ReentrantLock не реализует AuntoClosable, а, во-вторых, потому что try-with-resources каждый раз требует объявления новой переменной, а нам надо, чтобы lock-объект был один для всех потоков.
Lock называется reentrant, потому что поток может несколько раз повторно завладеть lock’ом, которым он уже владеет. Чтобы отпустить lock поток должен вызвать unlock() ровно столько раз, сколько был вызван lock() (внутри lock-объекта просто есть hold count, который следит за этим). Это необходимо для реализации вложенных вызовов методов, которые используют одни и те же lock объекты: например, если в примере выше у нас бы были защищены lock’ами методы transfer и getTotalBalance, то lock() будет вызван два раза: один раз после входа в transer, и ещё один раз после входа getTotalBalance.
Rule of thumb. В целом, короче, lock объекты надо использовать, когда один и тот же объект может быть в теории одновременно заппдейтчен из разных потоков, так что надо убедиться в том, что каждый поток полностью завершает свою работу с shared объектом прежде, чем к нему получит доступ другой объект.
Каким образом выбирается поток, который следующим войдёт в критическую секцию. У ReentrantLock есть конструктор с флагом fair, если выставить его, то будет выбран тот поток, который ждал дольше всего, а по умолчанию, видимо, выбирается тот, у которого больше приоритет. Однако этот при кол нужно использовать только, если точно знаешь, что ты делаешь, потому что нет гарантии, что thread scheduler тоже лучше относится к потокам, которые долго ждут.
Condition Objects
Описание проблемы. Даже, если поток получил доступ к критическому куску кода, может быть такое, что для него не выполнено какое-то условие, из-за которого он пока что не может выполнять никакую полезную работу в этом месте. Чтобы разобраться с такими случаями, есть condition objects или condition variables (исто рическое название просто). В случае с примером с банковскими счетами выше условием для возможности проведения транзакции будет наличие достаточного количества денег.
Нельзя просто в начале сделать проверку:
if (bank.getBalance(from) >= amount) {
bank.transfer(from, to, amount);
}
Потому что сразу после проверки управление может перейти другому потоку, который может снять все деньги с банковского счёта from, и тогда потом деньги снимутся вне зависимости от выполнения условия. Можно было бы запихнуть эту проверку внутрь критической секции, но тогда нам бы пришлось ждать внутри критической секции, пока кто-нибудь бы не добавил денег, чтобы можно было совершить транзакцию, но проблема в том, что тогда другие потоки не смогут войти в критическую секцию, так что даже в теории никто не сможет перечислить деньги.
public void transfer(int from, int to, double amount) {
lock.lock();
try {
while (accounts[from] < amount) {
// wait
}
// transfer
} finally {
lock.unlock();
}
}
Condition objects. Для этого как раз есть вот эти condition объекты. С lock объектом может быть ассоциирован один или несколько condition объектов. Condition объект можно достать из lock объекта с помощью метода lock.newCondition(). Условие нужно сохранить куда-нибудь, переменную (поле) с условием принято называть тем условием, которое должно выполниться, чтобы поток продолжил своё выполнение.
class Bank {
// то есть condition object у нас - это поле внутри объекта банка
private Condition sufficientFunds;
...
public Bank() {
...
sufficientFunds = lock.newCondition();
}
}
Condition wait set. Если в процессе выполнения транзакции мы обнаруживаем, что на счету недостаточно денег, то мы можем вызвать sufficientFunds.await(), чтобы отдать управление другим потокам. И управление к нему не перейдёт до тех пор, пока кто-то другой не вызовет sufficientFunds.signalAll(), а до тех пор поток будет оставаться в condition wait set’е для этого условия.
В нашем случае signalAll() должен быть вызван после того, как какой-то поток перечисляет кому-нибудь деньги, тогда есть шанс того, что условие выполнилось, и можно продолжать выполнение потоков, попавших в condition wait set. Вызов этого метода позволяет потоку снова запуститься, и тогда надо будет ещё раз проверить выполнение условие, потому что, опять же, нет гарантии, что оно выполнено.
Метод signal. Помимо signalAll есть ещё более эффективный метод signal, который разблокирует только один поток. Поэтому есть шанс того, что разблокируется поток, который ещё не готов к тому, чтобы разблокироваться, так что есть шанс того, что всё дедлокнется.
public void transfer(int from, int to, double amount) {
lock.lock();
try {
while (accounts[from] < amount) {
sufficientFunds.await();
}
// transfer funds
...
sufficientFunds.signalAll();
} finally {
lock.unlock();
}
}
В общем случае вот так:
while (!condition) {
conditionObject.await();
}
Deadlock. Очень важно, чтобы хотя бы кто-то вызвал signalAll(), чтобы не получилось так, что все потоки заблокировались, так что ни один из них не может быть возобновлён. Такая штука называется дедлоком.
Когда надо вызывать signallAll. В общем случае надо сигнализировать остальным потокам, что они могут попробовать возобновить свою работу, всякий раз, когда состояние объекта меняется так, что нужное условие в теории может быть удовлетворено.
Таким образом:
- Lock’и защищают куски кода, позволяя только одному потоку выполнять их.
- Lock’и менеджат потоки, которые пытаются войти в критический кусок кода.
- Lock может иметь один или несколько ассоциированных condition объектов.
- Condition’ы менеджат потоки, которые вошли в критический кусок кода, но не могут пройти дальше.