Оглавление
Java Concurrency 2
Synchronization (continued)
продолжение 14.5 в первой книжке core java
synchronized keyword, intrinsic condition and lock objects, (timed) tryLock, downsides of intrinsic locks, почему notify и wait не могут быть вызваны в несинхронизированных кусках кода, synchronized blocks, client-side locking, the monitor concept
volatile fields, JMM, мотивация, порядок выполнения чтений/записей относительно volatile полей (happens-before guarantee), в каких случаях достаточно/недостаточно использовать volatile, final variables
atomics, как использовать compareAndSet на примере нахождения максимального значения чего-то там, LongAdder/LongAccumulator
The synchronized Keyword
Intrinsic locks. Lock objects и condition objects — это относительно мощные инструменты и в большинстве случаев нам не нужен такой уровень контроля. Вместо этого можно использовать встроенный в язык инструмент. Каждый объект имеет в себе intrinsic lock. (Instrinsic function (или же built-in function) — это функция, реализация которой автоматически генерируется компилятором, это не совсем то же самое, что и inline function, потому что тут компилятор всё знает о функции, реализацию которой подставляет в method call.) Если пометить метод ключевым словом synchronized, то этот intrinsic lock защитит сразу весь метод. То есть вот это:
public synchronized void method() {
// method body
}
Эквивалентно вот этому:
public void method() {
this.intrinsicLock.lock();
try {
// method body
} finally {
this.intrinsicLock.unlock();
}
}
Intrinsic condition objects. Каждому intrinsic lock объекту соответствует единственный condition объект, ассоциированный с ним. Для взаимодействия с ним. Метод wait добавляет текущий поток в набор методов, ждущих выполнения условия (ему соответствует вызов intrinsicCondition.await()). Методы notify() и notifyAll() соответствуют вызовам instrinsicCondition.signal() и intrinsicCondition.signalAll().
Intrinsic locks for static methods. Ключевым словом synchronized можно пометить и статические методы. В таком случае lock и condition объекты будут содержаться внутри соответсвующего Class объекта, так что он будет ассоциирован с любыми вызовами статических объектов, так что, пока какой-то поток находится внутри одного из статических synchronized методов, то никакой другой synchronized метод из другого потока вызван быть не может, пока тот первый поток не выйдет из метода.
Минусы intrinsic lock’ов:
-
Нельзя прервать поток, который пытается получить lock в данный момент, потому что нет доступа к конкретному lock объекту. Но я не совсем понимаю, каким образом можно легально достать список ожидающих потоков.
-
В книжке написано, что you cannot specify a timeout when trying to acquire a lock. Я так понимаю, что это про методы
tryLock()и конкретно его timed версиюtryLock(long timeout, TimeUnit unit). ПростойtryLock()пытается получить lock, если он занят другим потоком, то он просто возвращаетfalseи сдаётся и не ждёт, пока другие потоки выйдут из критической секции. При этом даже, если в этот момент другие потоки тоже ждут, то вне зависимости от наличия fair ordering policy он войдёт в критическую секцию. Это такая странная, видимо, намеренная особенность этого метода.Timed версия этого метода, во-первых, ждёт некоторое время, чтобы попытаться войти в критическую секцию, а, во-вторых, этот метод учитывает fair ordering policy, так что его можно использовать с нулевым таймингом как альтернативу обычному
tryLock().Так вот, в случае с intrinsic lock’ом таких методов взаимодействия с ним нет.
-
Having a single condition per lock can be inefficient. Всё же с одним lock’ом может быть ассоциировано несколько условий. Если вызывается
waitсразу для всех потенциальных условий, то выполнение всех потоков, которые находятся в критических секциях, временно приостановится, пока не вызоветсяsignal. И, я так думаю, что из-за этого есть шанс того, что всё дедлокнется.
Кстати, ещё такое, что я пропустил: все эти методы wait, notify, notifyAll могут быть вызваны только внутри synchronized методов или блоков (ссыл ка). Потому что race condition. Например, если у нас есть такая штука:
// первый поток
while (!condition) { // 1
wait(); // 4
}
// второй поток
satisfyCondition(); // 2
notifyAll(); // 3
То может быть так, что первый поток проверяет условие, понимает, что оно не выполняется, и после этого момента управление передаётся во второй поток, который выставляет выполнение условия и уведомляет всех об этом, но первый поток ещё не находится в состоянии ожидания condition’а, так что это никак на него не влияет. И потом управление передаётся в первый поток, и он переходит в состояние ожидания.
Это объясняет, почему первый кусок кода должен быть синхронизирован. А необходимость в синхронизации второго куска кода объясняется тем, что надо синхронизировать работу с объектами, связанными с условием.
Synchronized Blocks
Можно ещё вот так acquire’ить intrinsic lock объекты:
synchronized (obj) {
// critical section
}
Ad hoc locks (exploiting intrinsic locks). И тогда никакой другой synchronized метод у obj не сможет быть вызван, пока какой-то поток находится в критической секции. Кстати, это можно использовать, чтобы неявно создать lock объект и не надо было писать вот ту дефолтную штуку с try-finally:
public class Clazz {
private Object lock = new Object();
public void doSomething() {
// ...
synchronized (lock) {
// critical section
}
// ...
}
}
Client-side locking. Если у нас есть какой-то класс с синхронизированными операциями и мы хотим реализовать какие-то ещё синхронизированные операции для него как пользователь класса, то можно попробовать сделать так:
public void doSomethingElse(Clazz obj) {
synchronized (obj) {
// critical section
}
}
Однако нет никакой гарантии, то объект будет использовать свой intrinsic lock, для своих синхронизированных методов, так что это всё жесть ненадёжно, целиком и полностью зависит от внутренней реализации класса.
The Monitor Concept
Monitor class — это по сути примерно вот эта штука с intrinsic lock’ами, которая реализует mutual exclusion для потоков и у неё есть механизм для уведомления ждущих потоков (condition variable). Конкретно там вот такие требования:
- A monitor is a class with only private fields
- Each object of the class has an associated lock
- All methods are locked by that lock
- The lock can have any number of associated conditions
И instrinsic lock’и не соответствуют этим требованиям как минимум в том, что поля могут не быть приватными, не все методы обязаны быть синхронизированными, и condition тут только один. И ещё instrinsic lock доступен клиентам (можно получить его в synchronized блоке). И, видимо, это небезопасно, потому что можно изменить извне состояние объекта таким образом, что какие-то потоки навсегда перейдут в состояние ожидания?
Volatile Fields
Memory model определяет то, каким образом потоки взаимодействуют с памятью компьютера (RAM), то есть, как связаны переменные в программе и то, как они сохраняются и достаются из памяти на низком уровне. В частности JMM — это Java Memory Model, она вот в частности определяет то, как разные потоки видят значения переменных, разделяемых между несколькими потоками. И проблема в том, что в JMM компилятор имеет большую свободу в том, как ему конкретно выполнять манипуляции с данными (из-за всяких оптимизаций, например, которые переставляют порядок инструкций), из-за чего переменная, разделяемая несколькими потоками, может иметь различные значения с точек зрения различных потоков. И это было в особенности критично в какой-то там старой JMM, сейчас этого вроде нет, например:
String s1 = "/usr/tmp";
String s2 = s1.substring(4); // contains "/tmp"
s2 использует тот же массив из символов, что и s1, но просто меняет сдвиг и длину, которые выставляются в конструкторе String. И со старой JMM было так, что можно было из другого треда увидеть, что offset у s2 равен не 4, а 0, из-за чего казалось, что внутри s2 не "/tmp", а "/usr".
Ну и ещё проблема в порядке выполнения чтений/записи при отсутствии синхронизации: компилятору позволено переставлять инструкции так, чтобы текущий поток разницы для себя не заметил. Из-за этого вот так писать:
// do the initializing
// ...
initialized = true;
Нельзя, потому что непонятно в рамках текущего потока, когда конкретно выставится флаг initialized.
Volatile keyword. (ссылка) В связи со всем этим есть ключевое слово volatile для полей, которое заставляет компилятор делать так, чтобы изменения для поля, помеченного этим словом, были одинаковыми одновременно для всех потоков. При этом это не гарантирует неделимость операций чтения/записи, это всё всё ещё может быть прерванным.
Это всё для того, чтобы значение отображалось корректно. Оно внутри по-другому как-то реализовано, но просто в качестве примера: CPU использует кэш в качестве буфера при записи/чтении, так что в общем случае без применения каких-то приколов (штуки для когерентности кэша — частный пример) может быть так, что из разных потоков одна и та же переменная видна с разными значениями, или ещё может быть так, что операции записи в неё из разных потоков видятся в разном порядке.
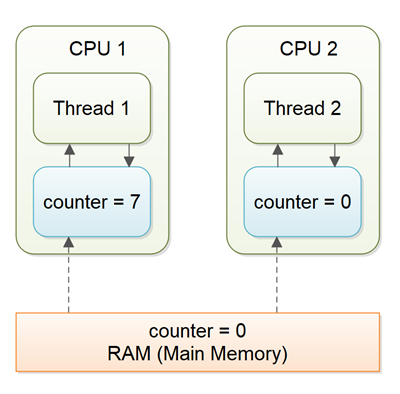
Кроме того, volatile поле выступает в роли memory barrier:
- компилятор не может переносить инструкции выше чтения из volatile поля
- компилятор не может переносить инструкции ниже записи в volatile поле
Так что с помощью volatile keyword можно пометить вот этот флаг initialized
// do the initializing
// ...
initialized = true;
И тогда вроде он будет корректно отображать то, когда что-то там на самом деле будет инициализировано.
Когда недостаточно объявить поле volatile. Как уже упоминалось, volatile не делает запись/чтение из поля неделимым: всё ещё может быть так, что выполнение присваивание будет прервано до того, как новое значение будет скопировано из кеша. И это всё особенно будет плохо, если новое значение поля вычисляется на основе старого. Тут придётся синхронизировать блок кода, который отвечает за увеличение переменной.
Но volatile приемлемо и нужно использовать, например, если один поток пишет, а другие — читают.
Final variables. Если поле объявлено как final, то его содержимое тоже будет видимым одинаково для всех остальных потоков: другие потоки получают к нему доступ только после того, когда ему будет присвоено какое-то конечное значение. То есть вот в таком случае:
final Map<String, Double> map = new HashMap<>();
гарантируется, что HashMap будет инициализирован прежде, чем к map кто-то из другого потока получит доступ.
Atomics
Atomics в джавававе — это всякие структуры данных из пакета java.util.concurrent.atomic, которые эффективно (эффективнее, чем с использованием lock’ов) реализуют всякие инструкции так, чтобы они были неделимыми. Например, AtomicInteger — это интеджер, у которого все операции неделимы. Например, инкремент AtomicInteger.addAndGet(int) не может быть прерван другими потоками.
Поиск максимального значения (пример). Тут всё немного сложнее, потому что нельзя просто сделать вот так:
largest.set(Math.max(largest.get(), observed));
Потому что после того, как вызовется largest.get(), у него есть шанс измениться в большую сторону, и тогда может всё заруиниться. Вместо этого такое можно делать в цикле с использованием метода AtomicInteger.compareAndSet(oldValue, newValue), который проверяет, актуально ли вот это старое значение и, если да, то оно меняет его на новое:
do {
oldValue = largest.get();
newValue = Math.max(oldValue, observed);
} while (!largest.compareAndSet(oldValue, newValue));
И это всё может показаться слишком медленным, потому что ты можешь потратить несколько попыток прежде, чем ты пройдёшь цикл без прерываний другими потоками, которые бы изменяли largest, но это всё ещё быстрее, чем использование lock’ов. Такая штука с тем, чтобы сохранить значение, а потом попробовать его использовать, называется оптимистичными апдейтами. Тот же механизм используется вроде как в реализации всех остальных “атомизированных” методах для работы с интеджером.
Но, начиная с Java 8 можно не использовать етот бойлерплейт код (boilerplate code — куски кода, которые много где повторяются with little or no alteration, вроде слышал, но забыл такое). Тут можно вот такое написать с использованием лямбд, особенно выглядит нормально:
largest.updateAndGet(x -> Math.max(x, observed));
// или вот так
largest.accumulateAndGet(observed, Math::max);
// последний метод эквивалентен вызову выше (ну, то есть там порядок аргументов такой же:
// первый аргумент - это предыдущее значение, а второе - то, которое передаётся
// в качестве аргумента)
LongAdder и LongAccumulator. Но по сути это просто удобная обёртка для того кода выше с оптимистичными апдейтами. Из-за этого, если очень много потоков одновременно пытаются обращаться к atomic интеджеру, то всё может начать очень сильно тормозить, потому что выполняется куча ретраев. В таких случаях можно использовать либо LongAdder, либо более общий вариант — LongAccumulator. Внутри себя они лениво сохраняют аргументы, с которыми вызываются операции, и только потом, когда потребуется финальное значение, оно вычисляется (ну, или, видимо, при переполнении таблицы внутри?). А ещё нужно иметь в виду, что порядок, в котором будет вычисляться итоговое значение, не определён (из описания LongAccumulator):
The order of accumulation within or across threads is not guaranteed and cannot be depended upon, so this class is only applicable to functions for which the order of accumulation does not matter.
Так что функция, передаваемая в LongAccumulator должна быть коммутативной и ассоциативной.
Аккумуляторы ненужны. При этом, наверное, имеет смысл просто самому сделать массив с переменной на каждый поток, или в каждый поток засунуть переменную, а потом просто всё просуммировать. И это не то чтобы сильно хуже или сложнее, но, возможно, даже эффективнее, чем использовать эту ерунду из стандартной библиотеки.