Оглавление
Линейные отображения. Действия с матрицами (продолжение)
продолжение 2.3 в первом томе кострикина
ранг произведения матриц (неравенство), квадратные матрицы, единичные/скалярные матрицы и их свойства, доказательство того, что только скалярные матрицы являются перестановочными с любыми другими квадратными матрицами, обратные матрицы, (не)вырожденные матрицы, теорема об обратимости матрицы
следствия из теоремы про обратимость матриц: неизменность ранга при домножении на невырожденную, обратимость из существования левой/правой обратной матрицы, матрица обратная произведению n невырожденных матриц
Ранг произведения матриц
Теорема. Пусть $A$ — произвольная матрица размера $m \times s$, $B$ — матрица размера $s \times n$. Тогда для них справедливо неравенство $\text{rank} AB \leq \min{\text{rank} A,\text{rank} B}$. То есть по сути это означает, что при перемножении двух матриц ранг не может увеличиться.
Доказательство. По определению произведения матриц:
\[C_{(i)} = A_{(i)}B \text{ - равенство для строк результирующей матрицы.}\\ С^{(j)} = AB^{(j)} \text{ - равенство для столбцов результирующей матрицы.}\]
Возьмём в качестве ранга матрицы $A$ её строчный ранг: $r_1 = \text{rank} A = \dim\left<A_{(1)},A_{(2)}, \dots, A_{(m)}\right>$. Не умаляя общности также примем строки $A_{(1)}, \dots, A_{(r_1)}$ за базисные, потому что перестановка строк — это элементарное преобразование, которое не изменит ранг ни матрицы $A$, ни $C$,
Из этого следует, что можно выразить все остальные строки матрицы $A$ через линейную комбинацию базисных строк, а значит, соответствующие строки матрицы $C$ тоже выражаются через первые свои $r_1$ строк:
\[C_{(k)} = A_{(k)} B = (\sum_{i = 1}^{r_1} \lambda_{ki} A_{(i)}) B = \sum_{i = 1}^{r_1} \lambda_{ki} (A_{(i)}B) = \sum_{i = 1}^{r_1} \lambda_{ki} C_{(i)}\]Из чего следует, что набор из первых $r_1$ строк матрицы $C$ как минимум является порождающим, так что $\text{rank} C \leq r_1 = \text{rank} A$. Аналогичным образом выводится, что $\text{rank} C \leq \text{rank} B\,\,\,\square$
Квадратные матрицы
Множество всех квадратных матриц порядка $n$ с вещественными коэффициентами обозначается как $M_n(\mathbb{R})$ или $M_n$. Можно также рассматривать это множество как векторное пространство (потому что выполняются все аксиомы (ассоциативность и дистрибутивность уже выводились ранее) и все операции замкнуты). Также говорят, что множество $M_n$ образует матричное (ассоциативное) кольцо, а с учётом того, что также выполняются свойства $\lambda AB = (\lambda A) B = A (\lambda B)$, множество $M_n$ также называется алгеброй матриц над $\mathbb{R}$. (Я не помню определение кольца, и даже не знаю определения алгебры, но, я так понимаю, всё это будет объяснено позже.)
Также, говоря о квадратных матрицах, надо обратить внимание на единичные матрицы, которые определяются вот так: $E_n := (\delta_{kj})$, где $\delta_{kj}$ — это символ Кронекера, который определяется вот так:
\[\delta_{kj} = \begin{cases} 1, \text{ если } k = j \\ 0, \text{ если } k \not = j \end{cases}\]Свойства единичных и скалярных матриц. Очевидно, что для единичных матриц верно, что $\text{rank} E_n = n$. А ещё верно то, что $EA = A = AE$ для любой матрицы $A \in M_n$. И вот так в общем случае: $\text{diag}_n(\lambda) A = \lambda A = A\, \text{diag}_n(\lambda)$, где $\text{diag}_n(\lambda)$ определяется как $\text{diag}_n(\lambda) = \lambda E$ — это скалярная матрица.
Теорема. Если $A \in M_n$ — такая матрица, что она перестановочна со всеми матрицами из $M_n$ (то есть $AB = BA,\, \forall B \in M_n$), то она должна быть скалярной.
Доказательство. Определим матрицу $E_{ij}$ как матрицу, в которой элемент $(i, j)$ равняется единице, а остальные — нулевые. Если $A$ — та перестановочная матрица из определения теоремы, то для неё выполнится равенство $A E_{ij} = E_{ij}A,\,\forall i,j$. Можно расписать произведение матриц вот так:
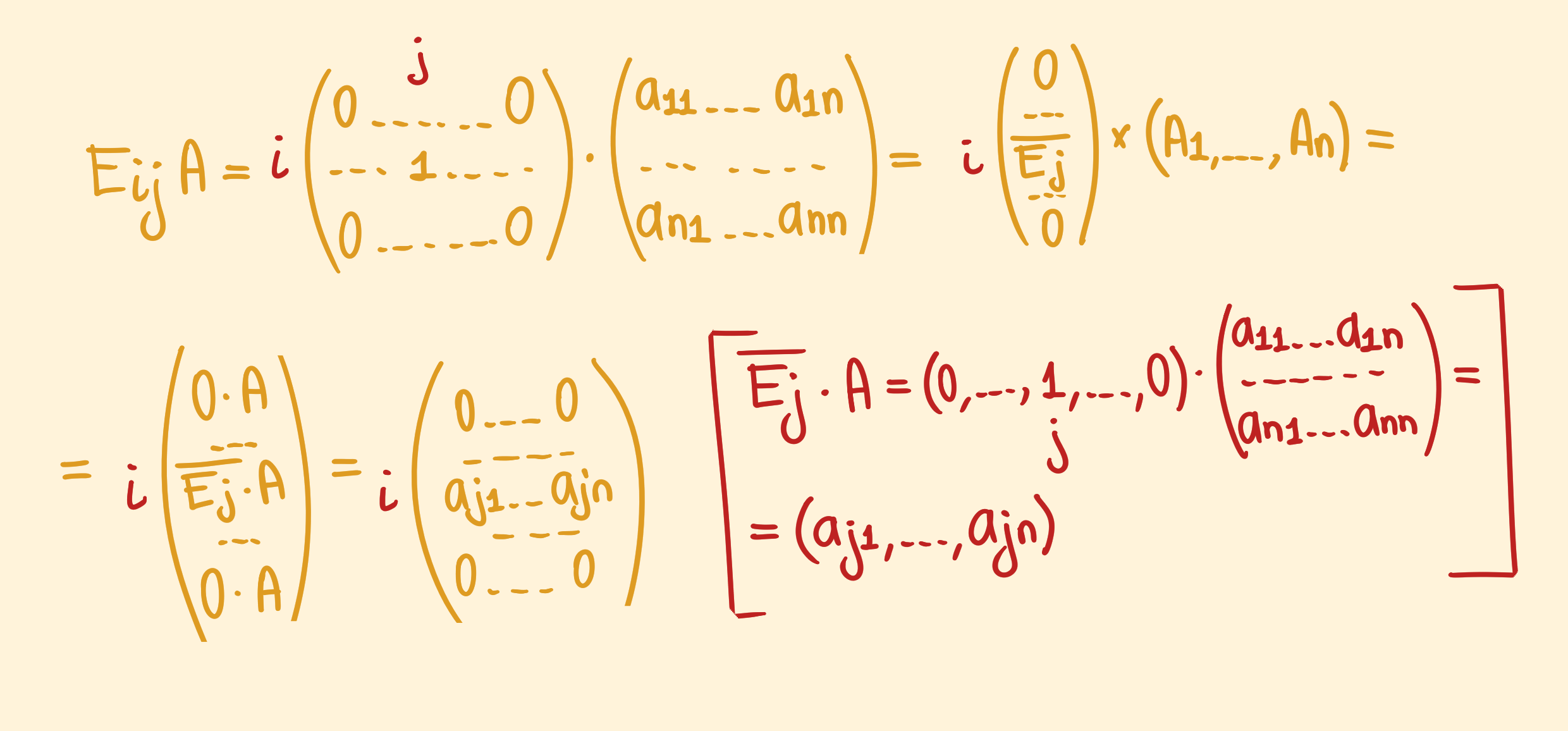
Аналогично можно расписать произведение $A E_{ij}$ (получится единственный ненулевой $j$-ый столбец). И в силу равенства:
\[\left(\begin{matrix} 0 & \dots & 0 \\ \dots & \dots & \dots \\ a_{j1} & \dots & a_{jn} \\ \dots & \dots & \dots \\ 0 & \dots & 0 \end{matrix}\right) = E_{ij}A = A E_{ij} = \left(\begin{matrix} 0 & \dots & a_{1i} & \dots & 0 \\ \dots & \dots & \dots & \dots & \dots\\ 0 & \dots & a_{ni} & \dots & 0 \end{matrix}\right)\]Из этого следует, что $a_{jk} = 0,\, \forall k\not = j$ и $a_{jj} = a_{ii}$. Задавая разные значения $i$ и $j$ выводится, что все диагональные элементы равны, а те, что находятся не на диагонали, равны нулю. То есть $\text{diag}_n(\lambda) = A\,\,\square$
Обратные матрицы
Единственность обратной матрицы. Для данной квадратной матрицы $A \in M_n$ может существовать такая матрица $A’ \in M_n$, чтобы выполнялось соотношение $AA’ = E_n = A’A$. Сразу же можно вывести единственность такой матрицы при условии её существования. Если существует другая матрица $A’’$ такая, что $AA’’ = A’‘A = E$, то: $A’’ = A’’ E = A’’ (AA’) = (A’’ A) A’ = E A’ = A’$.
Такая матрица называется обратной к $A$ и обозначается как $A^{-1}$. Если для матрицы существует обратная, то она называется обратимой.
Определение. Матрица $A \in M_n(\mathbb{R})$ называется невырожденной, если $\text{rank} A = n$. Если же $\text{rank} A \lt n$, то матрица называется вырожденной.
Теорема. Матрица $A \in M_n$ является обратимой тогда и только тогда, когда она не является вырожденной.
Доказательство $(\implies)$ Предположим, что матрица является обратимой, из чего следует в частности, что $AB = E$. $n = \text{rank} E = \text{rank} AB \leq \min {\text{rank}A, \text{rank} B} \leq n$. Последнее неравенство просто следует просто из того, что $A,B \in M_n$. Из этого следует, что $\min {\text{rank}A, \text{rank} B} = n \implies \text{rank} A = n,\,\,\text{rank} B = n\,\,\square$
Доказательство $(\impliedby)$ Предположим теперь, что $\text{rank} A = n$. Из этого следует, что все столбцы матрицы $A$ линейно независимы, а значит, их линейная комбинация порождает всё пространство $\mathbb{R}^n$ и являются базисными для него. Так что можно выразить стандартный базис через этот другой базис:
\[E^{(j)} = \sum_{i = 1}^n a_{ij}' A^{(i)}\]Координаты для стандартного базиса в терминах нового можно выписать в виде матрицы из $M_n$, причём выписать их по столбцам. Назовём эту матрицу $A’$.
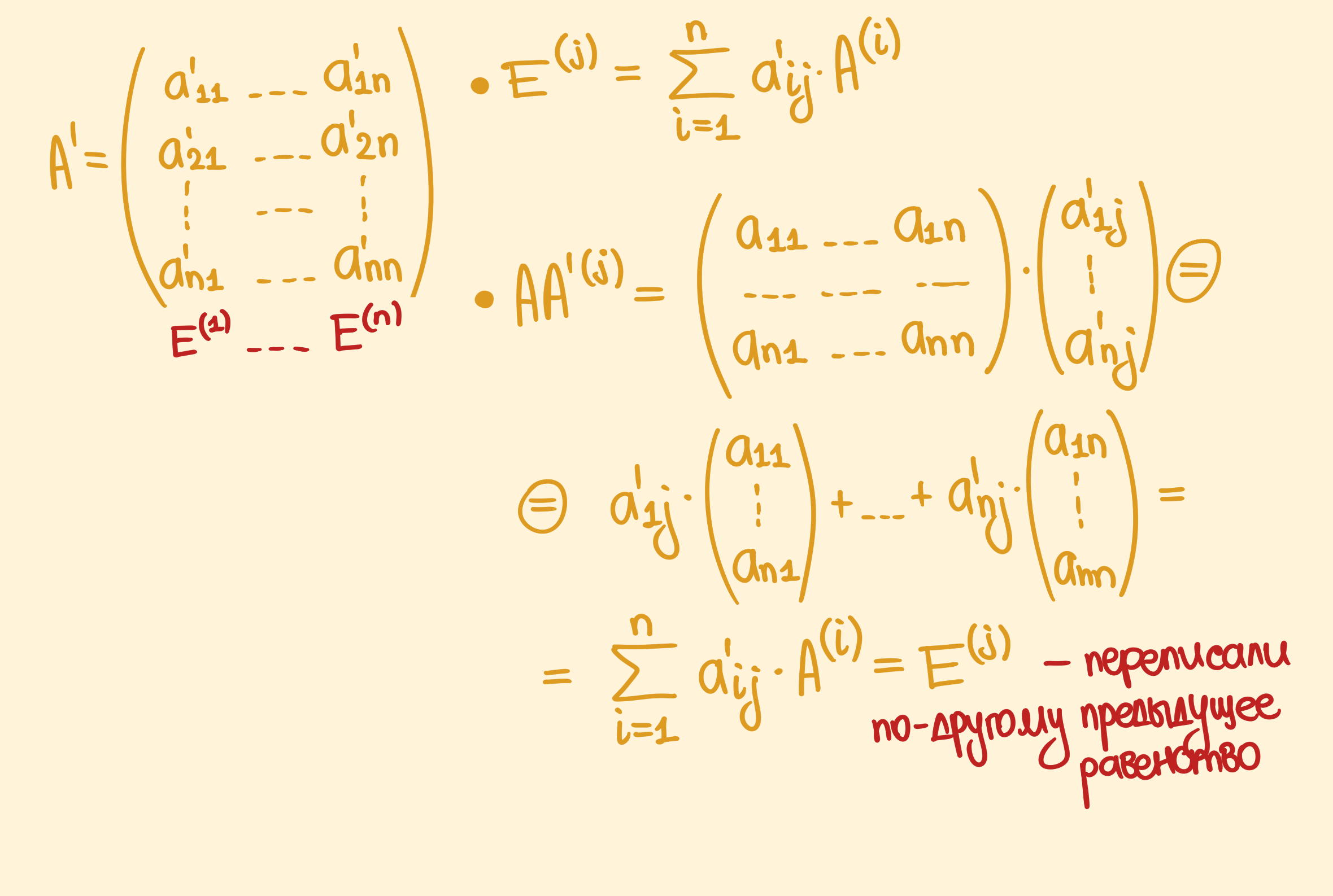
Равенство выше можно немного переписать:
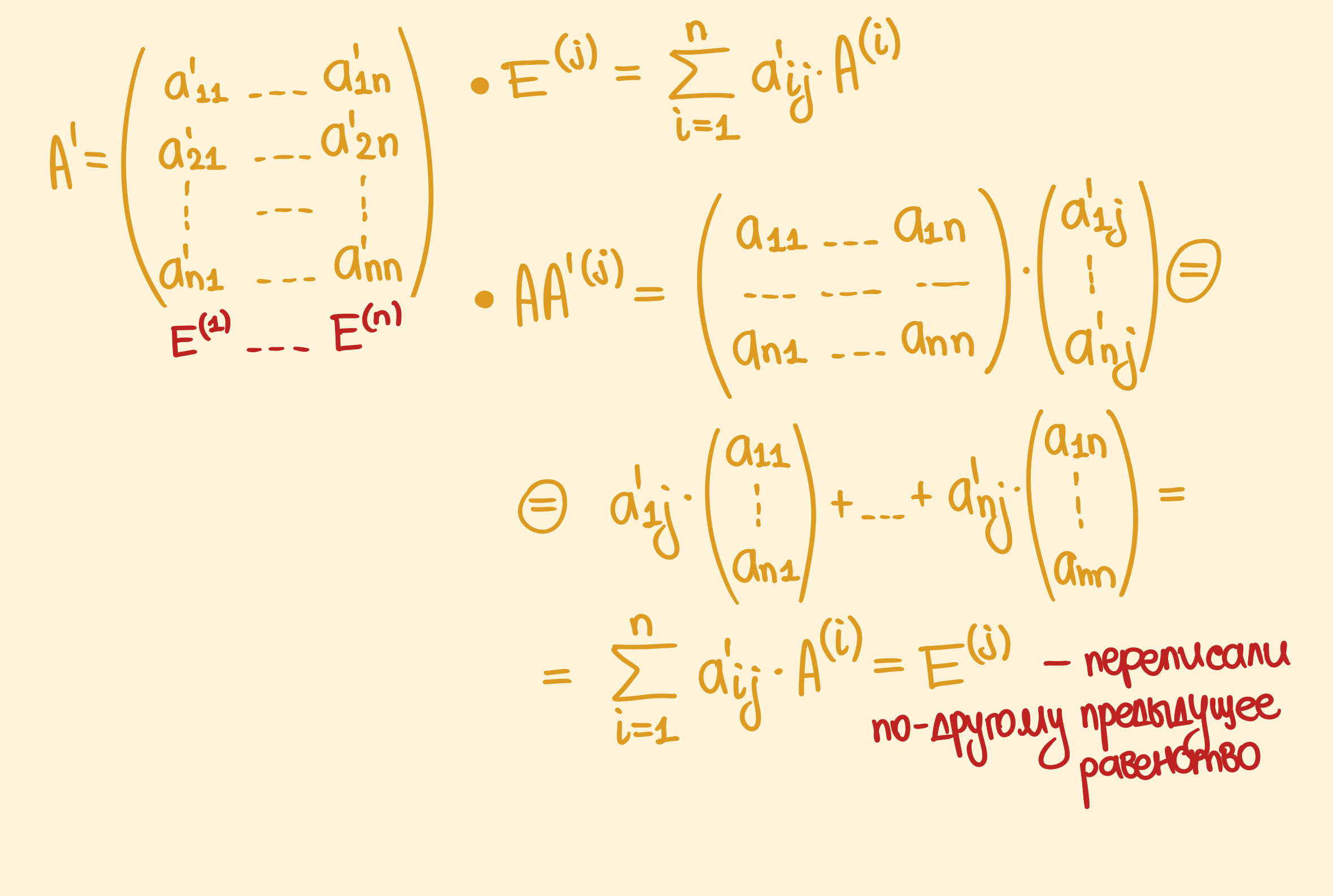
И тогда получится, что $E = (E^{(1)}, \dots, E^{(n)}) = (AA’^{(1)}, \dots, AA’^{(n)}) = AA’$. То есть нашли обратную к $A$ справа. Теперь можно проделать всё то же самое для транспонированной матрицы $A^T$. Для неё найдётся такая матрица $B$, что $A^T B = E \implies E = E^T = (A^T B)^T = B^T (A^T)^T = B^T A$. Так что нашли обратную слева $A’’ = B^T$.
Допустим, есть обратная справа: $AA’ = E$. $A’’ = A’’ E = A’’ (AA’) = (A’’ A) A’ = E A’ = A’$. То есть, если есть обратные слева и справа, то они будут обязательно равны. Так, доказали, что у невырожденной матрицы есть обратная $\square$
Следствия из теоремы про существование обратной матрицы
Теорема. Если $B \in M_m,\, \text{rank}B = m$ и $C \in M_n,\, \text{rank} C = n$, и $A$ — матрица $m \times n$, то:
\[\text{rank} BAC = \text{rank}A\]Доказательство. Так как при умножении матрицы на другую матрицу её ранг не увеличивается, то:
\[\text{rank} BAC = \text{rank} (BA)C \leq \text{rank BA} = [\text{в силу невырожденности матрицы }C]\\ = \text{rank}(BA(CC^{-1})) = \text{rank}((BAC)C^{-1}) \leq \text{rank}(BAC)\]Из этого следует, что $\text{rank}BAC = \text{rank} BA$. Аналогично:
\[\text{rank}BA \leq \text{rank} A = \text{rank}B^{-1} (BA) \leq \text{rank} BA\]И отсюда уже следует $\text{rank}BAC = \text{rank}BA = \text{rank}A\,\,\square$
Теорема. Если $A,B \in M_n$ и $AB = E$ или $BA = E$, то из этого сразу следует, что $B = A^{-1}$.
Доказательство. $n = \text{rank} E = \text{rank} AB \leq \text{rank} A \leq n \implies \text{rank} A = n$. То есть невырожденность следует только лишь существования левого/правого обратного, а не обратимости в целом. А по доказанной теореме, раз есть невырожденность, то есть и обратимость $\square$
Теорема. Если $A,B,\dots,C,D \in M_n$ — невырожденные матрицы, то их произведение, тоже будет невырожденной матрицей (ну, это очевидно из того первого следствия про ранг матрицы, умноженной слева и справа на невырожденные матрицы $\text{rank} BAC = \text{rank}A$), и ещё имеет место вот такое равенство:
\[(AB\dots CD)^{-1} = D^{-1} C^{-1}\dots B^{-1} A^{-1}\]Доказательство. Можно проверить, просто умножив вручную и воспользовавшись предыдущей теоремой, чтобы не надо было проверять обратимость и слева, и справа:
\[(AB\dots CD) (D^{-1} C^{-1} \dots B^{-1} A^{-1}) = AB\dots C(DD^{-1})C^{-1}\dots B^{-1} A^{-1} = \dots = E\,\,\square\]
